最近,有消息透露渤海银行前副行长靳超即将加入平安养老,担任总经理一职。值得一提的是,平安养老现任董事长甘为民也是中国平安引入的银行系高管,他此前在重庆银行担任董事长。
研究公司Epoch AI预测,到2028年互联网上所有高质量的文本数据都将被使用完毕,机器学习数据集可能会在2026年前耗尽所有“高质量语言数据”。
研究人员指出,用人工智能(AI)生成的数据集训练未来几代机器学习模型可能会导致“模型崩溃”(model collapse)。
AI大模型训练数据是否短缺这一话题再次成为近期众多媒体关注的热点。
近日,《经济学人》杂志发布题为《AI 公司很快将耗尽大部分互联网数据》(AI firms will soon exhaust most of the internet's data)的文章,指出随着互联网高质量数据的枯竭,AI领域面临“数据墙”。对于AI大模型公司来说,现在的挑战是找到新的数据源或可持续的替代品。
该篇文章援引研究公司Epoch AI的预测,到2028年互联网上所有高质量的文本数据都将被使用完毕,机器学习数据集可能会在2026年前耗尽所有“高质量语言数据”。这种现象在业内被称为“数据墙”。如何应对“数据墙”是当下AI公司面临的重大问题之一,可能也是最有可能减缓其训练进展的问题。文章指出,随着互联网上的预训练数据枯竭,后期训练变得更加重要。标签公司如Scale AI和Surge AI每年通过收集后期训练数据赚取数亿美元。
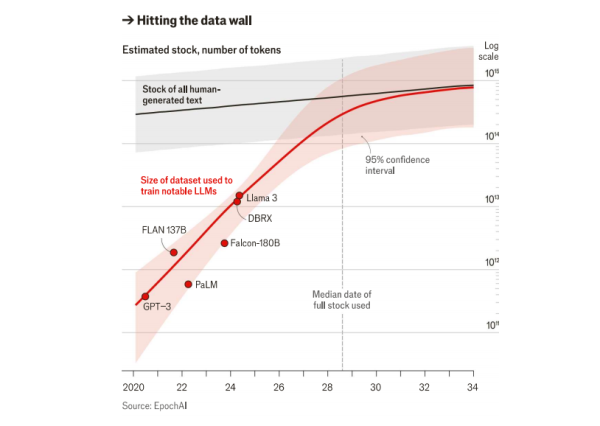
《经济学人》杂志援引Epoch AI图
事实上,业界早有关于“数据枯竭”的声音。澎湃科技注意到,2023年7月初,加州大学伯克利分校计算机科学教授、《人工智能——现代方法》作者斯图尔特·罗素(Stuart Russell)曾发出警告,ChatGPT等人工智能驱动的机器人可能很快就会“耗尽宇宙中的文本”,通过收集大量文本来训练机器人的技术“开始遇到困难”。
但业内也有不同的声音。2024年5月,在接受彭博社科技记者艾米丽·张(Emily Chang)的采访时,著名计算机科学家、斯坦福大学人工智能实验室联合主任、斯坦福大学教授李飞飞曾明确表示,她并不赞同“我们的人工智能模型正在耗尽用于训练的数据”这一较为悲观的看法。李飞飞认为,这一观点过于狭隘。仅从语言模型的角度来看,当下仍有大量的差异化数据等待挖掘,以构建更为定制化的模型。
当下,为了应对训练数据有限的问题,解决方案之一便是使用合成数据,这些数据是机器创建的,因此是无限的。但合成数据也有合成数据的风险,国际学术期刊《自然》于7月24日发表一篇计算机科学论文指出,用人工智能(AI)生成的数据集训练未来几代机器学习模型可能会污染它们的输出,这个概念称为“模型崩溃”(model collapse)。由于模型是在被污染的数据上训练出来,最终会误解现实。
研究团队在研究中表明,在大语言模型学习任务中安全的杠杆炒股平台,底层分布的尾部很重要,大规模使用大语言模型在互联网上发布内容,将污染用于训练其后继者的数据收集工作,今后人类与大语言模型交互的真实数据将越来越有价值。不过,研究团队也提到,AI 生成数据并非完全不可取,但一定要对数据进行严格过滤。比如,在每一代模型的训练数据中,保持10% 或20% 的原始数据,还可以使用多样化数据,如人类产生的数据,或研究更鲁棒的训练算法。